
Extracción de texto del contenido mediante ranuras HTML, plantillas HTML y Shadow DOM
Nombres de capítulos de libros, citas de un discurso, palabras clave de un artículo, estadísticas de un informe: todos estos son tipos de contenido que podrían resultar útiles para aislar y convertir en un resumen de alto nivel de lo que es importante.
Por ejemplo, ¿ha visto la forma en que Business Insider proporciona los puntos clave de un artículo antes de entrar en el contenido?
Ese es el tipo de cosas que vamos a hacer, pero intentaremos extraer los puntos destacados directamente del artículo utilizando HTML Slot, HTML Template y Shadow DOM.
Estas tres especificaciones titulares se utilizan normalmente como parte de componentes web: módulos de elementos personalizados totalmente funcionales destinados a ser reutilizados en páginas web.
Ahora, lo que pretendemos hacer, es decir, la extracción de texto, no necesita elementos personalizados, pero puede hacer uso de esas tres tecnologías.
Existe un enfoque más rudimentario para hacer esto. Por ejemplo, podríamos extraer texto y mostrar el texto extraído en una página con algún script básico sin utilizar ranura ni plantilla. Entonces, ¿por qué usarlos si podemos optar por algo más familiar?
La razón es que el uso de estas tecnologías nos permite un código de marcado preestablecido (también opcionalmente, estilo o script) para nuestro texto extraído en HTML. Lo veremos a medida que avanzamos con este artículo.
Ahora, como una definición muy diluida de las tecnologías que usaremos, diría:
- Una plantilla es un conjunto de marcas que se pueden reutilizar en una página.
- Un espacio es un marcador de posición para un elemento designado de la página.
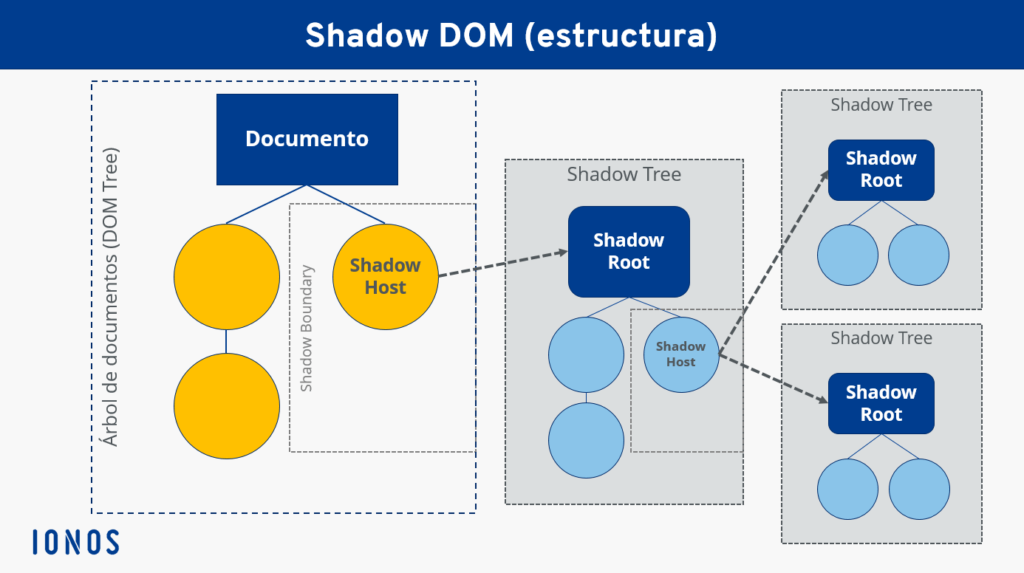
- Un DOM oculto es un árbol DOM que realmente no existe en la página hasta que lo agregamos mediante un script.
Los veremos con un poco más de profundidad una vez que entremos en la codificación. Por ahora, lo que vamos a hacer es un artículo que sigue con una lista de puntos clave del texto. Y probablemente lo hayas adivinado, esos puntos clave se extraen del texto del artículo y se compilan en la sección de puntos clave.
Los puntos clave se muestran como una lista con un diseño entre los puntos. Entonces, primero creamos una plantilla para esa lista y diseñamos un lugar para que vaya a la lista.
article!-- Article content --/article!-- Section where the extracted keypoints will be displayed --section id='keyPointsSection' h2Key Points:/h2 ul!-- Extracted key points will go in here --/ul/section!-- Template for the key points list --template id='keyPointsTemplate' lislot name='keyPoints'/slot/li li#x2919;mdash;#x291a;/li/templateLo que tenemos es una semántica sectioncon un ullugar donde irá la lista de puntos clave. Luego tenemos uno templatepara los elementos de la lista que tiene dos lielementos: uno con un slotmarcador de posición para los puntos clave del artículo y otro con un diseño centrado.
El diseño es arbitrario. Lo importante es colocar un slotlugar donde irán los puntos clave extraídos . Lo que sea que esté dentro templateno se representará en la página hasta que lo agreguemos a la página mediante un script.
Además, al marcado interior templatese le puede aplicar estilo utilizando estilos en línea o CSS encerrado por style:
template id='keyPointsTemplate' lislot name='keyPoints'/slot/li li#x2919;mdash;#x291a;/li style li{/* Some style */} /style/template¡La parte divertida! Escojamos los puntos clave del artículo. Observemos el valor del nameatributo para el slotinterior de template( keyPoints) porque lo necesitaremos.
article h1Bears/h1 pBears are carnivoran mammals of the family Ursidae. spanspan slot='keyPoints'They are classified as caniforms, or doglike carnivorans/span/span. Although only eight species of bears !-- more content -- and partially in the Southern Hemisphere. spanspan slot='keyPoints'Bears are found on the continents of North America, South America, Europe, and Asia/span/span.!-- more content --/p pWhile the polar bear is mostly carnivorous, !-- more content --. Bears use shelters, such as caves and logs, as their dens; spanspan slot='keyPoints'Most species occupy their dens during the winter for a long period of hibernation/span/span, up to 100 days./p !-- More paragraphs -- /articleLos puntos clave están envueltos en un spanvalor slotde atributo (“ keyPoints“) que coincide con el namemarcador slotde posición dentro del template.
Observe también que agregó otro exterior spanque envuelve los puntos clave.
El motivo es que los nombres de los espacios suelen ser únicos y no se repiten, ya que se slothace coincidir un elemento con un nombre de espacio. Si hay más de un elemento con el mismo nombre de espacio, el slotmarcador de posición se reemplazará por todos esos elementos de forma consecutiva, y el último elemento será el contenido final en el marcador de posición.
Entonces, si comparamos ese único slotdentro de templatecon todos los spanelementos con el mismo slotvalor de atributo (nuestros puntos clave) en un párrafo o en todo el artículo, terminaríamos con solo el último punto clave presente en el párrafo o el artículo en lugar del slot.
Eso no es lo que necesitamos. Necesitamos mostrar todos los puntos clave. Entonces, estamos volviendo los puntos clave con un exterior spanpara hacer coincidir cada uno de esos puntos clave individuales por separado con el slot. Esto es mucho más obvio al mirar el guión, así que hagámoslo.
const keyPointsTemplate = document.querySelector('#keyPointsTemplate').content;const keyPointsSection = document.querySelector('#keyPointsSection ul');/* Loop through elements with 'slot' attribute */document.querySelectorAll('[slot]').forEach((slot)={ let span = slot.parentNode.cloneNode(true); span.attachShadow({ mode: 'closed' }).appendChild(keyPointsTemplate.cloneNode(true)); keyPointsSection.appendChild(span);});Primero, recordaremos cada uno spancon un slotatributo y obtendremos una copia de su padre (el externo span). Tenga en cuenta que también podemos recorrer el exterior spandirectamente si lo deseamos, dándoles un classvalor común.
Luego, la copia exterior spanse adjunta con un árbol de sombra ( span.attachShadow) formado por un clon del contenido de la plantilla ( keyPointsTemplate.cloneNode(true)).
Este “adjunto” hace que el slotelemento interior de la lista de la plantilla en el árbol de sombra absorba el interior spanque lleva su nombre de ranura correspondiente, es decir, nuestro punto clave.
Luego, el punto clave ranurado se agrega a la sección de puntos clave al final de la página ( keyPointsSection.appendChild(span)).
Esto sucede con todos los puntos clave a lo largo del ciclo.
Eso es realmente todo. Hemos capturado todos los puntos clave del artículo, hemos hecho copias de ellos y luego hemos colocado las copias en la plantilla de lista para que todos los puntos clave estén agrupados y proporcionen un pequeño y agradable resumen del artículo similar a CliffsNotes.
Aquí está esa demostración una vez más:
¿Qué opinas de esta técnica? ¿Hay algo que sería útil en contenido extenso, como publicaciones de blogs, artículos de noticias o incluso entradas de Wikipedia? ¿Qué otros casos de uso se te ocurren?
El valor práctico del HTML semántico
HTML, CSS y nuestros puntos de entrada en la industria en desaparición
Comprender por qué el HTML semántico es importante, según lo explica TypeScript
Crear un juego de estacionamiento con la API HTML de arrastrar y soltar

¿Por qué no agregamos un elemento “encantador” al HTML?
Diseñar para la web debería significar crear HTML y CSS.
Subir
Deja una respuesta